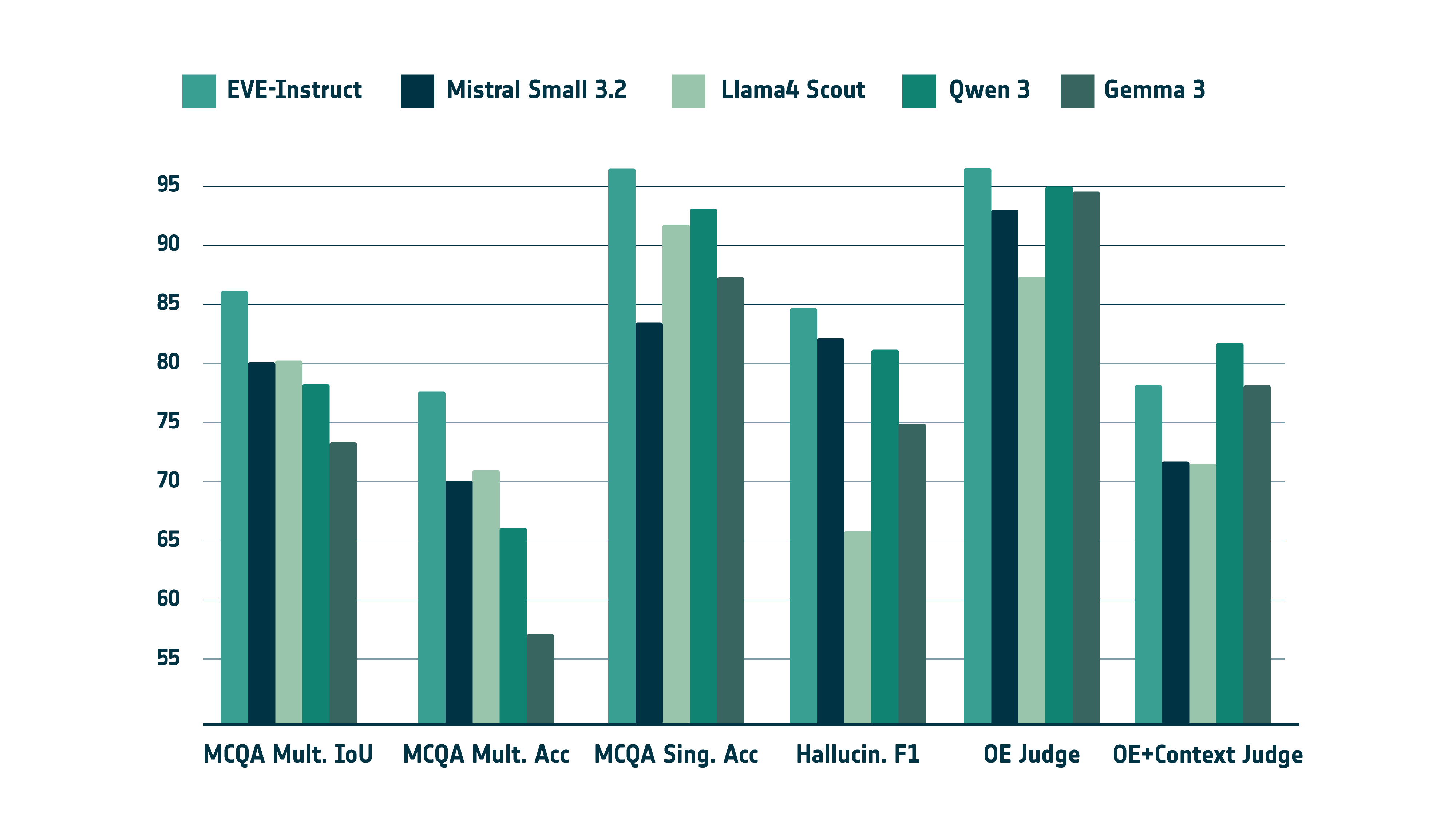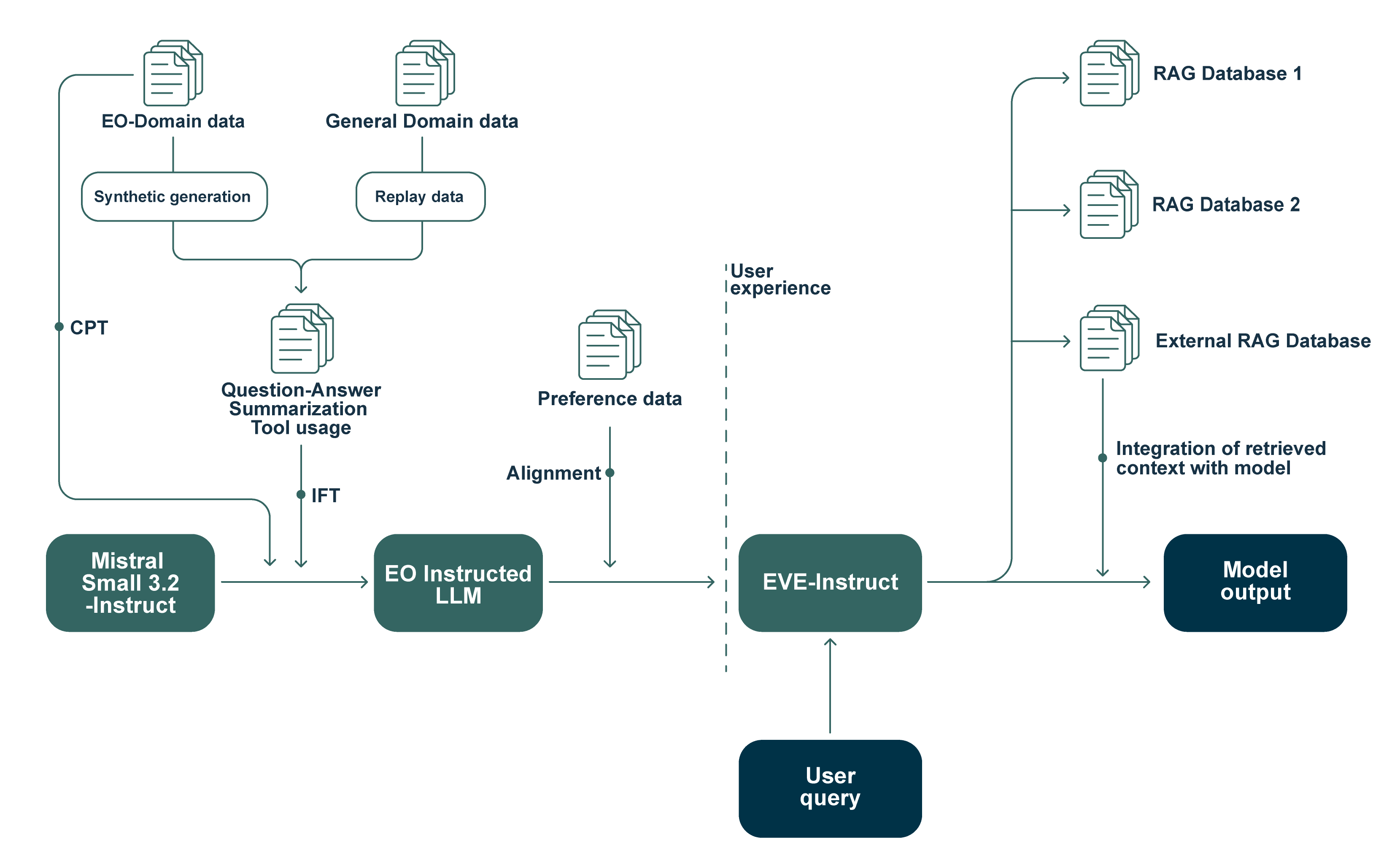
To address the lack of standardized evaluation in Earth Observation and Earth Sciences, we introduce the first manually curated benchmark suite for domain LLMs. The dataset contains 5,693 samples created through human–LLM generation and expert review by 25 domain specialists.
The benchmark evaluates multiple capabilities essential for Earth Intelligence:
- Multiple-choice QA (single and multiple answers)
- Open-ended QA (with and without retrieval context)
- Hallucination detection and factual reliability
Across this suite, EVE-Instruct achieves the strongest overall performance among comparable models in its size range, leading on multiple-choice QA, hallucination detection, and open-ended QA while remaining competitive when retrieval context is provided.